

Building Out Effective Agentic Evaluation Systems

2025 is shaping up to be the year of AI agents. Gokul Rajaram of Marathon predicts, “the next big thing in 2025 will be a turning point when the tools and systems for building AI agents become more sophisticated ... mak[ing] it possible for semi-independent AI agents to become genuinely useful [1].” Similarly, Jamie Cuffe of New Company anticipates “web usage shifting from humans to agents [1].” There is a growing consensus that AI assistance can extend well beyond chatbots into impactful real-world applications. At OpenMind, we’ve been at the forefront of developing these agent-based tools, and it’s exciting to see the industry’s forecasts echo the very approaches we’ve championed.
In these real-world scenarios, multiple agents are bound to coexist, often coordinating and interacting in large numbers. Without rigorous alignment on reliability, retrieval accuracy, relevance, interpretability, ethical behavior, and overall system performance (including latency and token cost), agents risk producing contradictory outcomes or amplifying biases. Robust evaluation is thus essential to elevate prototypes from toy use cases to production-ready systems, especially in enterprise and commercial settings.
At OpenMind, our focus on thorough evaluation is integral to bridging innovation and real-world impact. By enforcing stringent testing and measurement frameworks, we ensure our agent framework meets the highest standards for reliability, ethical responsibility, and scalability. In doing so, we empower enterprises and developers to confidently adopt agentic solutions.
How Evaluation Works in Traditional LLMs
Historically, AI systems have relied on benchmarks to evaluate performance. With an offline method of evaluation (see Figure 1), requests and outputs can come from an evaluation set, which allows for observability of the agent prior to deployment [2]. These methods typically provide visibility into core capabilities, including accuracy, reliability, safety, latency, relevance, and bias detection. For example, one can introduce unit testing with “gold-standard” references to gauge the system’s consistency and trustworthiness in a controlled setting. Doing so establishes a baseline of performance and serves as a prerequisite before moving into more dynamic, real-world evaluations.
Popular benchmark suites include GSM8K (for grade-school math), HumanEval (for coding tasks), and MMLU (covering massive multitask language understanding in areas like law and mathematics) [3]. Additionally, community-driven platforms like the Hugging Face Open LLM Leaderboard compare open-source LLMs, providing further insight into how agentic systems might stack up against various performance baselines [3]. Many evaluations also take place in controlled or simulated environments like puzzle-solving or game-based benchmarks, which can offer consistent comparisons across different types of AI models.

Limitations of Evaluation for AI Agents Today
While these methods are valuable for establishing a baseline, they often fall short of capturing the complexities that emerge when AI agents are deployed at scale. Evaluating AI agents is far from straightforward because these systems entail a level of complexity that surpasses traditional LLMs. They integrate multiple components, ranging from contextual understanding and environment interactions to advanced decision-making frameworks, making performance assessment a nuanced process.
In fact, Liang et al. observed that “the reference summaries in standard summarization datasets (e.g., CNN/DM, XSUM) are actually worse (under the same human evaluations) [4].” This discrepancy can stem from inflated performance (e.g., when training data overlaps with the evaluation set) leading to overfitting on specific tasks.
Moreover, results are susceptible to prompt dependency and model-specific configurations (e.g., hyperparameter tuning), making it difficult to replicate outcomes consistently. As top-performing models increasingly match or even surpass human-level performance on benchmark tests, the discriminative power of these assessments diminishes, offering limited insights for more advanced or nuanced applications.
Finally, the quality and relevance of many evaluation tasks remain a concern: outdated or biased questions and metrics reliant on exact matches often fail to reflect the diversity and complexity of real-world contexts. Real-world scenarios, especially in high-stakes industries such as finance or health, demand more nuanced evaluation strategies. Agents must handle messy data, edge cases, and competing priorities, conditions rarely mirrored in controlled lab settings. It’s clear that use-case-specific evaluations, grounded in rigorous research, are essential stepping stones toward genuine multi-agent orchestration. By examining how agents adapt to dynamic inputs, coordinate with other systems, and maintain reliability under unpredictable circumstances, organizations can pinpoint and proactively address critical limitations before widely deploying agent-based solutions.
Agentic AI calls for both qualitative and quantitative metrics, given that success may hinge on subtle aspects of task execution, contextual reasoning, and adaptive decision-making. Consequently, the standard benchmarks designed for LLMs cannot be directly applied to agent-based systems without risking incomplete or misleading assessments.
Solution 1: Use-Case-Specific Evaluation
Use-case-specific design principles remain essential to evaluate AI agents effectively. For example, a finance bot might be tested against an evolving set of financial regulations, verifying that new answers remain compliant. In healthcare, AI systems must protect patient privacy while adhering to medical protocols, tracking patient outcomes and the ability to accommodate a broad range of demographics. Additionally, customer service systems often rely on traditional metrics like first-contact resolution, and these can be enriched by examining user feedback on empathy, escalation handling, and tone of voice.
Solution 2: Agent <> Human-Coordinated Evaluation
In practice, the most robust evaluation frameworks blend domain-specific metrics with oversight from external agents and human stakeholders. For instance, an LLM-as-a-Judge approach leverages large language models, or specialized evaluators built on top of these models, to assess the outputs of other models under a structured rubric. This rubric explicitly outlines evaluation criteria and scoring guidelines, making it easier to scale than purely manual assessments. However, this setup introduces its own challenges: biases and limitations in the “judge” model can propagate through the entire system, prompting the perennial question, “Who validates the validators?”
To mitigate such concerns, many organizations implement human-in-the-loop review. By incorporating human oversight, teams gain a level of context-aware scrutiny that automated systems often lack. Human evaluators can detect subtle factors like tone, creativity, or hidden biases, and other elements that numeric scores (e.g., BLEU or ROUGE) might miss. While human-in-the-loop methods can be resource-intensive, strategies such as multi-rater evaluations and clearly defined ground truths help minimize individual biases and ensure a more robust feedback loop.
A complementary mechanism for scaling such evaluation processes is crowdsourced LLM evaluation. An arena-like platform, such as Chatbot Arena (lmarena.ai), allows diverse user groups to compare multiple model outputs head-to-head [6]. This yields broad, high-volume feedback on user preferences and perceived model quality, which can then be augmented by domain experts who focus on more specialized or high-stakes use cases. By layering these methods, i.e., combining automated, crowd-based assessments with human-in-the-loop oversight and domain-specific metrics, teams can capture both rapid, wide-ranging insights and deep, context-sensitive validation.
Solution 3: Real World Performance Evaluation
Unlike offline or controlled benchmarks, a real-world evaluation approach assesses agent performance in real time (see below) [5]. Rather than relying exclusively on fixed datasets and predefined prompts, this method observes how agents respond to live, ever-changing inputs. Evaluators track system outputs as they are produced, gaining immediate insights into how well an agent handles the messiness of real-world context, ranging from shifting regulatory environments to dynamic user requests.
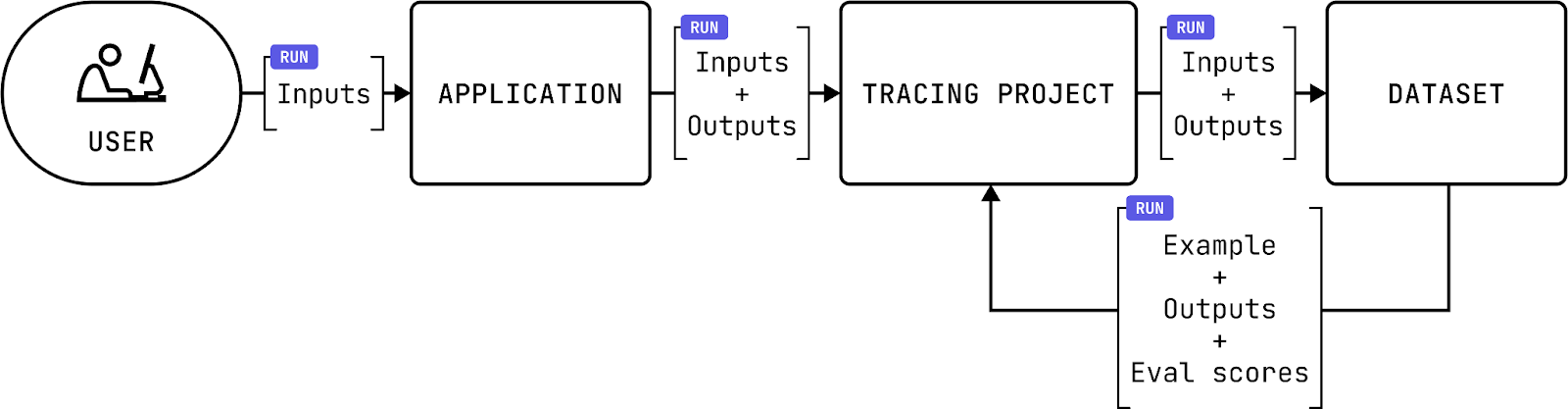
Such a multifaceted approach captures subtle indicators of quality that static benchmarks typically miss. Although real time evaluation is not inherently “better” than offline methods, and would have high requirements on the promptness of data transfer, it complements them by highlighting how agents behave under real-life constraints. By integrating practical constraints early, ranging from compliance requirements to interpersonal cues, organizations can develop a more predictive and holistic view of agent performance.
At OpenMind, we combine our own metric with domain-specific performance scores to achieve a more holistic evaluation. In concrete terms, we track the difference between the tasker’s willingness-to-pay (WTP) for the agent’s output and the agent’s own WTP (i.e., the resources or “cost” it must expend). A narrower gap signifies stronger value alignment, reflecting both task relevance and cost-effectiveness. We then layer on an aggregated, domain-specific score that captures the agent’s performance across dimensions such as accuracy, latency, ethical compliance, and domain relevance. By getting the weighted average of these two metrics (as represented in the equation below, we gain a multidimensional view of each agent’s performance—measuring not just how well the agent accomplishes a task, but also whether its operational costs and benefits are aligned with user priorities, a critical requirement for real-world, production-ready agentic systems. We also ensure that this equation is adjusted for any extraneous time-to-completion and quality/relevance-degradation penalty terms.
where W is the maximum the tasker is willing to pay, B_i is the agent i’s bid, E_i is the aggregate evaluation score of agent i, and T is any relevant penalty terms. α, β ≥ 0 are weighting coefficients chosen by the tasker.
Future Outlook
Looking ahead, there are several exciting directions for advancing agentic evaluation as AI systems evolve. The first is regarding a more refined human-in-the-loop methodology. Improved rubrics and guided feedback mechanisms, potentially aided by reward/incentive modeling or preference-based reinforcement learning, will help translate nuanced user intent into consistent, measurable metrics. Complementing these advancements, crowd-sourced, decentralized evaluation frameworks will leverage distributed networks of evaluators to provide diverse, real-world perspectives and ensure broader coverage of edge cases. Blockchain-based reputation systems and incentive structures can enhance accountability and transparency in this process, bridging the gap between raw model outputs and the real-world requirements of end users while aligning AI behavior more closely with human expectations.
Furthermore, with multimodal LLMs increasingly handling text, images, audio, and video, evaluators need expanded metrics that account for cross-modal consistency. Instead of relying on text-only conversions or purely manual inspections, holistic evaluations would incorporate multimodal checks—for instance, verifying that a generated image accurately reflects its textual caption or that a video segment aligns with an accompanying transcript. Moving toward shared multimodal benchmarks and consistency metrics will standardize these evaluations, promoting more robust comparisons across different models and architectures.
Combined with complementary offline and online methods, these future directions ensure that AI-driven solutions not only excel in controlled benchmarks but also perform reliably and ethically in the dynamic contexts where they matter most. The future of agent evaluation isn’t just automated—it’s collaborative, multimodal, and human-aligned.
Works Cited
[1] Cuffe, Jamie. "Next Big Thing 2025." Substack, https://nbt.substack.com/p/nextbigthing2025.
[2] Castells, Manuel. "Title of Paper." Information Retrieval Journal, 2020, https://castells.github.io/papers/irj2020.pdf.
[3] "NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Queries." ResearchGate, https://www.researchgate.net/publication/384211183_NaturalCodeBench_Examining_Coding_Performance_Mismatch_on_HumanEval_and_Natural_User_Queries.
[4] "HELM." Stanford Center for Research on Foundation Models, 17 Nov. 2022, https://crfm.stanford.edu/2022/11/17/helm.html.
[5] Zhang, Wei, et al. "A Comparison of Offline Evaluations, Online Evaluations, and User Studies." ResearchGate, https://www.researchgate.net/publication/265551457_A_comparison_of_Offline_Evaluations_Online_Evaluations_and_User_Studies.
[6] "Chatbot Arena." LM Arena, https://lmarena.ai/.